
この記事は「タイタニックデータセット」を使って、前処理から、簡易な分類機械学習モデルXGBoostを用いて予測まで行うまでの一連の流れを解説する入門記事です。
初心者向けに「とりあえず動かす」ことを目的に、基本的なデータ処理とモデル構築の基礎を学ぶことができるよう作りました。
また、より本格的な機械学習をする上での続編もタイタニックデータでやっていく予定なので、よろしければ見てみてください!
タイタニックデータは以下のkaggleサイトで無料ダウンロードできるものを使っていきます。

タイタニックデータとは
Titanicデータセットは、Kaggleで最も有名な初心者向けコンペティションの一つです。乗客の情報(年齢、性別、乗船クラスなど)をもとに「生存したかどうか」を予測する問題です。
このデータには、次のような特徴があります。
- 二値分類問題:生存(1)または死亡(0)を予測
- 実世界のデータに近い:欠損値や文字列データ、カテゴリデータを含む
- シンプルだが学びが多い:データ前処理、特徴量エンジニアリング、モデル選択の重要性がよくわかる
そのため、機械学習を学び始めたばかりの人にとって、「データをきれいにすること」「モデルを作ること」「予測して提出すること」の基本を一通り経験できる格好の教材となっています。
この章では、Titanicデータを使って、まずは「とにかく動かす」ことを目標に進めていきます。
ソースコード全体
まずはソースコードの全体を以下に示します。その後、一つ一つ解説します!
import pandas as pd
import xgboost as xgb
# データ読み込み
df_train = pd.read_csv("data/train.csv")
df_test = pd.read_csv("data/test.csv")
# 欠損値を見つける
print("--column with Nan in train")
for column in df_train.columns:
if df_train[column].isnull().any():
print(column)
print("--column with Nan in test")
for column in df_test.columns:
if df_test[column].isnull().any():
print(column)
# 欠損補完
df_train["Age"].fillna(df_train["Age"].mean(), inplace=True)
df_train["Cabin"].fillna(df_train["Cabin"].mode()[0], inplace=True)
df_train["Embarked"].fillna(df_train["Embarked"].mode()[0], inplace=True)
df_test["Age"].fillna(df_test["Age"].mean(), inplace=True)
df_test["Fare"].fillna(df_test["Fare"].mean(), inplace=True)
df_test["Cabin"].fillna(df_test["Cabin"].mode()[0], inplace=True)
# 不要列削除
df_train.drop(["Name", "Ticket", "Cabin"], axis=1, inplace=True)
df_test.drop(["Name", "Ticket", "Cabin"], axis=1, inplace=True)
# エンコード
df_train["Sex"] = df_train["Sex"].replace({"male": 0, "female": 1})
df_test["Sex"] = df_test["Sex"].replace({"male": 0, "female": 1})
df_train = pd.get_dummies(df_train)
df_test = pd.get_dummies(df_test)
# 列を揃える
df_test = df_test.reindex(columns=df_train.columns.drop("Survived"), fill_value=0)
# x, y分割
train_x = df_train.drop(["PassengerId", "Survived"], axis=1)
train_y = df_train["Survived"]
test_x = df_test.drop(["PassengerId"], axis=1)
# モデル学習
clf = xgb.XGBClassifier(random_state=0)
clf.fit(train_x, train_y)
# 予測
result = clf.predict(test_x)
# 結果出力
output = pd.DataFrame({
"PassengerId": df_test["PassengerId"],
"Survived": result
})
output.to_csv("result.csv", index=False)
ソースコード詳解
データの読み込み
# データ読み込み
df_train = pd.read_csv("data/train.csv")
df_test = pd.read_csv("data/test.csv")まずは、Titanicデータ(train.csvとtest.csv)をPandasで読み込みます。
train:モデルに学習させるためのデータ
test:学習済みモデルに対して「生存・死亡」を予測するデータ
読み込んだら、以下のようにデータの中身を確認することもできます。
train.head()
test.head()この時点で注目するポイント
- testには”Survived”列がない(→ ここを予測する)
- 数値型と文字列型が混在している
- いくつかの列にNaN(欠損値)が存在する
これらをもとに、次の前処理方針を立てます。
列名とデータタイプの確認
Titanicデータセットには以下のような列があります。
| 列名 | 内容 |
|---|---|
| PassengerId | 乗客ID |
| Survived | 生存フラグ(0=死亡, 1=生存) |
| Pclass | チケットクラス(1st, 2nd, 3rd) |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 同乗している兄弟姉妹・配偶者の数 |
| Parch | 同乗している親・子供の数 |
| Ticket | チケット番号 |
| Fare | 運賃 |
| Cabin | 客室番号 |
| Embarked | 出港地(C=シェルブール, Q=クイーンズタウン, S=サウサンプトン) |
ここで重要なのは、「どの列をモデルに使い、どの列を削除するか」を判断することです。
例えば、名前やチケット番号は、直接生存に関係なさそうなので削除対象になります。
欠損値の可視化
まず、欠損の有無を確認します。
# 欠損値を見つける
print("--column with Nan in train")
for column in df_train.columns:
if df_train[column].isnull().any():
print(column)
print("--column with Nan in test")
for column in df_test.columns:
if df_test[column].isnull().any():
print(column)このコードの出力は以下のようになります。
--column with NaN in train
Age
Cabin
Embarked
--column with NaN in test
Age
Fare
Cabinつまり、trainにはAge、Cabin、Embarkedに欠損値が、testにはAge、Fare、Cabinに欠損値があることがわかりました。
欠損値の補完
今回はひとまず、以下の方針で欠損値を埋めてみました。
Age,Fare→ 平均値で補完(連続値なので)Cabin,Embarked→ 最頻値で補完(カテゴリ的な情報だから)
# 欠損補完
df_train["Age"].fillna(df_train["Age"].mean(), inplace=True)
df_train["Cabin"].fillna(df_train["Cabin"].mode()[0], inplace=True)
df_train["Embarked"].fillna(df_train["Embarked"].mode()[0], inplace=True)
df_test["Age"].fillna(df_test["Age"].mean(), inplace=True)
df_test["Fare"].fillna(df_test["Fare"].mean(), inplace=True)
df_test["Cabin"].fillna(df_test["Cabin"].mode()[0], inplace=True)文字列 → 数値への変換
基本的に、機械学習アルゴリズムは数値データしか扱えません。
したがって、文字列データを適切に変換する必要があります。
Sex(性別)を 0(male)/1(female)に変換Embarked(乗船地)はダミー変数化- ダミー変数化すると、例えば
Embarked_S,Embarked_C,Embarked_Qのように各港の情報が0/1で表現されます。
- ダミー変数化すると、例えば
Name,Ticket,Cabinは削除(意味が薄い+処理が大変)
# 不要列削除
df_train.drop(["Name", "Ticket", "Cabin"], axis=1, inplace=True)
df_test.drop(["Name", "Ticket", "Cabin"], axis=1, inplace=True)
# エンコード
df_train["Sex"] = df_train["Sex"].replace({"male": 0, "female": 1})
df_test["Sex"] = df_test["Sex"].replace({"male": 0, "female": 1})
df_train = pd.get_dummies(df_train)
df_test = pd.get_dummies(df_test)
説明変数/目的変数への分割
- X_train: 説明変数(特徴量)
- y_train: 目的変数(生存かどうか)
train_x = df_train.drop(["PassengerId", "Survived"], axis=1)
train_y = df_train["Survived"]
test_x = df_test.drop(["PassengerId"], axis=1)XGBoost で学習
# モデル学習
clf = xgb.XGBClassifier(random_state=0)
clf.fit(train_x, train_y)ここではXGBoost(決定木ベースの勾配ブースティング手法)を使用します。
シンプルな設定ですが、Titanic程度の難易度であれば十分良い結果が得られます。
random_state=0を指定して、結果の再現性を持たせています。
テストデータの予測 & CSV 出力
# 予測
result = clf.predict(test_x)
# 結果出力
output = pd.DataFrame({
"PassengerId": df_test["PassengerId"],
"Survived": result
})
output.to_csv("result.csv", index=False)- 予測された生存フラグ(0または1)を、PassengerIdと紐づけてCSV出力
- Kaggle提出用のフォーマットに合わせる(列順・列名に注意!)
これで、Kaggleに提出可能なresult.csvが完成します!
データ提出
こちらの「Submit Prediction」から提出します。
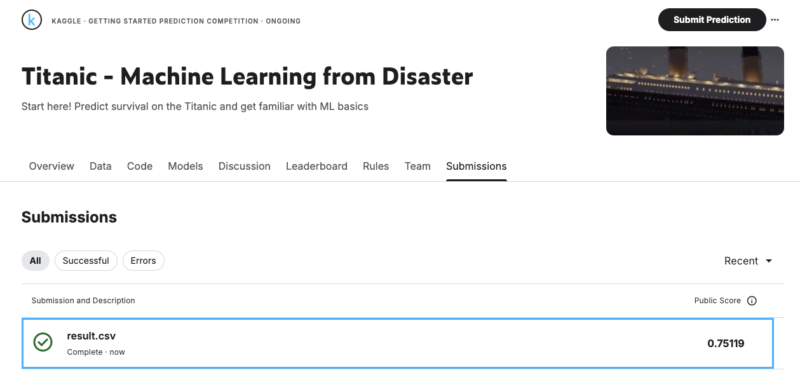
私の環境では、0.75119でした。だいたいこのくらいであればうまくいってると思います!
おわりに
この章では、タイタニックデータを使って、機械学習モデルの基本的な流れを一通り体験しました。
- データを読み込み
- 欠損値を処理し
- 文字列を数値に変換して前処理を整え
- 説明変数と目的変数に分けて
- モデルを学習させ
- テストデータに対して予測を行い
- 予測結果をKaggleに提出できる形式にまとめる
という一連のプロセスを、「最短」で動かすことを目標に進めました。
「単にコードを写すだけではなく、なぜこの処理が必要なのかを理解する」を意識すると定着しやすいと思います!
次回はクロスバリデーションをやってみます。



コメント