
今回は言わずと知れた機械学習の練習教材であるタイタニックデータでクロスバリデーションをしてみます。
前回の記事で作成したデータを用いてStratifiedKFoldを用いたクロスバリデーションをやってみましょう!

クロスバリデーション(交差検証)とは?
- 機械学習のモデルが本当に汎用的に使えるか(過学習してないか)確かめるための方法です。
- データを「訓練データ」と「検証データ」に分けて、何度も学習・検証を繰り返します。
単純に一回だけ train/test に分けるよりも、データの分割による偶然の偏りを減らせるので、作成したモデルやデータに対して信頼できる精度評価ができます。
StratifiedKFoldとは?
- Stratified(層化) → クラス分類問題で、各クラスの比率を保ったままデータを分割する方法
- KFold(K分割) → データをK個に分ける方法
つまり、StratifiedKFoldは:
「ラベルの比率をできるだけ保ったまま、データをK分割する」
タイタニックでいうならラベルは目的変数のSurvived列に対応します。
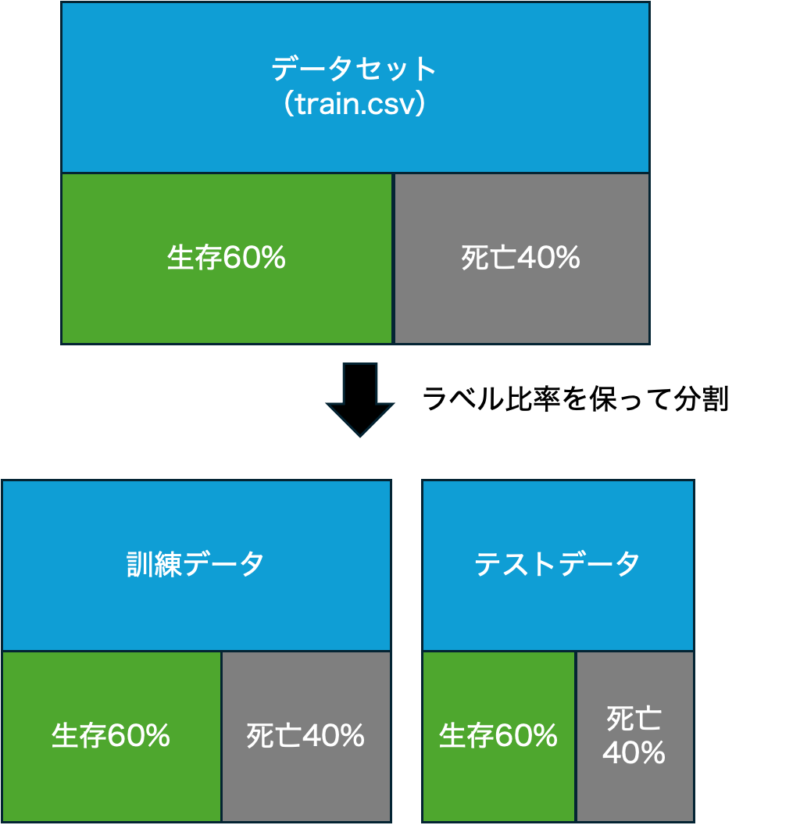
“ラベルの比率を保つ”とは、Titanicのデータ全体を見ると、
- 死亡した人(Survived = 0)の方が多くて、
- 生存した人(Survived = 1)は少ない
つまり、もともと クラスの比率に偏りがある データです。
例えば(ざっくりですが):
| クラス | 割合 |
|---|---|
| 死亡 (0) | 62% |
| 生存 (1) | 38% |
くらいだったりします。
StratifiedKFoldがやってくれることは?
分割するときに、
この62% vs 38%の比率を、各fold内でもできるだけ保つ ということです。つまり、
- あるfoldのtrainデータにも、だいたい6:4くらいで死亡/生存が入ってる
- 同じfoldのtestデータにも、6:4くらいで死亡/生存が入ってる
みたいにしてくれるわけです。
実践したコード
データの準備
# 前回作成したデータ
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
df_train = pd.read_csv("data/train.csv")
# 欠損値を埋める
df_train["Age"] = df_train["Age"].fillna(df_train["Age"].mean())
df_train["Cabin"] = df_train["Cabin"].fillna(df_train["Cabin"].mode()[0])
df_train["Embarked"] = df_train["Embarked"].fillna(df_train["Embarked"].mode()[0])
# 列の削除、エンコード
# 削除→Name, Ticket, Cabin
df_train.drop(["Name", "Ticket", "Cabin"], axis=1, inplace=True)
# 性別の0,1化
df_train["Sex"] = df_train["Sex"].replace({"male": 0, "female": 1})
# ダミー変数化
df_train = pd.get_dummies(df_train)クロスバリデーション
# ラベル(目的変数)と特徴量の分離
train_y = df_train["Survived"]
train_x = df_train.drop("Survived", axis=1)
# クロスバリデーション設定
cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=0)
accuracies = []
# 各foldで学習・予測・評価
for fold, (train_idx, val_idx) in enumerate(cv.split(train_x, train_y), 1):
# データの分割
X_train = train_x.iloc[train_idx]
y_train = train_y.iloc[train_idx]
X_val = train_x.iloc[val_idx]
y_val = train_y.iloc[val_idx]
# モデルの初期化と学習
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# 検証データで予測
y_pred = model.predict(X_val)
# 精度の評価と記録
acc = accuracy_score(y_val, y_pred)
accuracies.append(acc)
print(f"Fold {fold}: Accuracy = {acc:.4f}")
# クロスバリデーション全体の平均精度
print(f"Average Accuracy: {np.mean(accuracies):.4f}")私の環境では以下の出力でした。以下、実行したコードを一つ一つ解説します。
Fold 1: Accuracy = 0.7946
Fold 2: Accuracy = 0.7879
Fold 3: Accuracy = 0.7879
Average Accuracy: 0.7901コードの解説
cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=0)- StratifiedKFoldを設定
shuffle=True: データを事前にシャッフル(クラスの偏りを減らす)random_state=0: シャッフルの再現性を確保(毎回同じ結果になる)
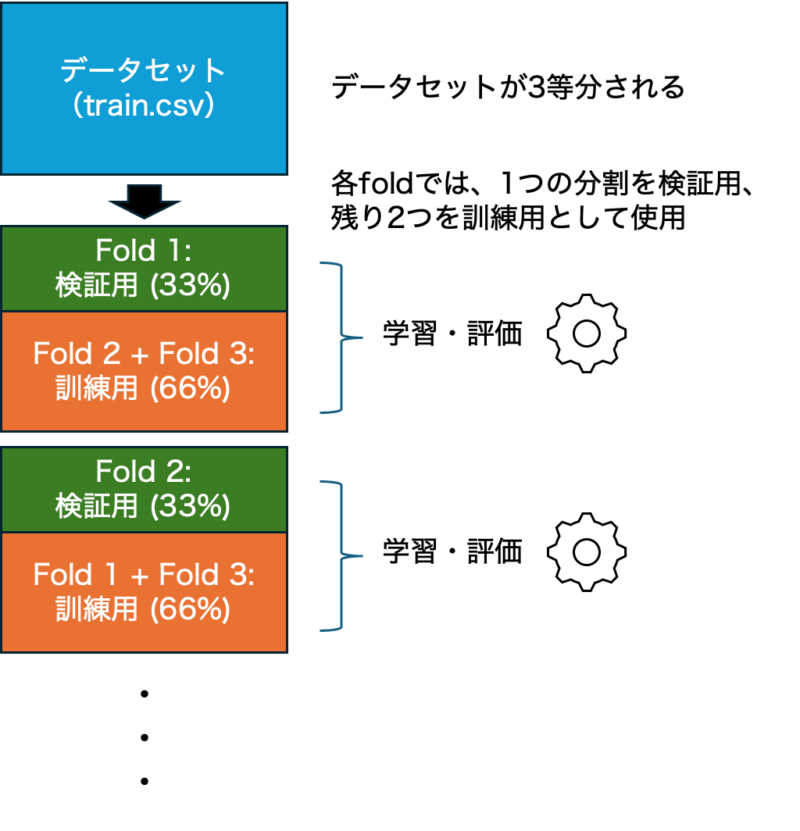
for fold, (train_idx, val_idx) in enumerate(cv.split(train_x, train_y), 1):- cv.split(train_x, train_y) は交差検証用にデータを3分割して、各foldに対して以下を順に返します:
(train_idx, val_idx)
train_idx: トレーニング用データのインデックス(行番号)val_idx: バリデーション用データのインデックス(行番号)、
つまりtrain_xやtrain_yを「訓練用」と「検証用」に分けたときの、それぞれのデータに対応する行番号です。
このcv.split()は 3回分の (train_idx, val_idx) を返します(3分割だから)。それをfor文で繰り返し処理しているわけです。 - 各foldでは、1つの分割を検証用、残り2つを訓練用として使用します。これを 3回繰り返して、すべてのデータを1回ずつ検証に使うということです。つまり、約33%のデータが検証用に使われます。
- enumerate関数は繰り返し処理の中で「何回目のループか(= fold番号)」を一緒に取ってくるための関数です。この「何回目か」がfoldになります。
- ここでのイメージは以下のような図で表せます。
X_train = train_x.iloc[train_idx]
y_train = train_y.iloc[train_idx]
X_val = train_x.iloc[val_idx]
y_val = train_y.iloc[val_idx]train_x: 特徴量のDataFrame(説明変数だけ、つまり “Survived”列を除いたもの)train_y: ラベルのSeries(目的変数、”Survived”列)- X_val, y_valは検証用のX,yです。
train_idx,val_idx: StratifiedKFoldによって得られた**インデックス(行番号)**の配列.iloc[]は pandas の行番号ベースのインデックス指定です。
つまり、train_x.iloc[train_idx] は、train_xの中から「train_idxに該当する行」だけを取り出しています。
(train_idxはnumpy配列ですが、.ilocはそれを受け取ってくれます)
# モデルの初期化と学習
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# 検証データで予測
y_pred = model.predict(X_val)- 分類モデルのオブジェクトを作成し、学習していない状態の空のモデルを定義します。その後X_train, y_trainを用いて学習します。
- 学習済みの
modelを使って、X_val(検証用の説明変数)に対して「生存 or 死亡」を予測(分類)しています。
# 精度の評価と記録
acc = accuracy_score(y_val, y_pred)
accuracies.append(acc)
print(f"Fold {fold}: Accuracy = {acc:.4f}")y_valは 検証データの正解ラベル(Survived: 0 or 1)、y_predは モデルが予測したラベルです。- accuracy_scoreは正しく分類されたサンプルの割合(精度)を返します。つまり何%正解してるか、がわかります。
- 各foldで計算した精度(
acc)をリストaccuraciesに追加していきます。クロスバリデーションなので、このリストにはn_splitsの数だけスコアが入ります(今回は3個)。
# クロスバリデーション全体の平均精度
print(f"Average Accuracy: {np.mean(accuracies):.4f}")- 最後に
np.mean(accuracies)として平均精度を計算しました。
おわりに
今回は、タイタニックデータを使ったStratifiedKFoldによるクロスバリデーションの流れを整理してみました。
実践を通して、層化分割(Stratified Split)によるラベル比率の維持や、各foldでの学習・検証サイクルをしっかり理解できたと思います。
ただし、今回のコードでは 「前処理を全データに対して実施してからクロスバリデーションを回している」 ため、
軽微とはいえ データリーク が発生しています(平均値や最頻値による欠損補完など)。
この問題は、Pipeline という仕組みを使うことで、
「各foldの訓練データだけに対して前処理を行う」形に改善できます。
この部分については、次回の記事で詳しく解説していこうと思います!
ここまで読んでいただき、ありがとうございました!

コメント